Cross-region disaster recovery in Aiven for PostgreSQL® Limited availability
The cross-region disaster recovery (CRDR) feature ensures your business continuity by recovering your workloads to a remote region in the event of a region-wide failure.
Region-wide outage
CRDR allows you to cope with the primary region failure by initiating a recovery transition to another region. To identify a region outage, look into the region status:
- Check your monitoring and alerts, and watch the following metrics:
- Instances, nodes, services failures
- Connectivity loss, latency spikes, packet drops
- High error rates, timeouts, 5xx server errors
- Check your cloud provider's status page:
- Test connectivity and DNS resolution for your instances or services.
CRDR overview
The CRDR setup is a pair of integrated multi-node services, sharing credentials and a DNS name but located in different regions. CRDR peer services can be hosted on 1-3 nodes.
- Primary service hosted in the primary region is your original service you use on regular basis. It hands over to the recovery service when you initiate a failover or a switchover. When you initiate a failback or a switchback, the primary service takes back control from the recovery service as soon as the infrastructure is up and running again.
- Recovery service hosted in the recovery region is the service you create for disaster recovery purposes. It takes over from the primary service when you initiate a failover or a switchover. When you initiate a failback or a switchback, the recovery service hands over to the primary service as soon as the infrastructure is up and running again.
The CRDR cycle is a sequence of actions involving CRDR peer services aimed at enabling and executing CRDR as well as resuming the original service operation.
Throughout the CRDR cycle, CRDR peer services or service nodes go into the following states:
-
Active: A CRDR peer service is active when it runs on a node that is replicating data to CRDR standby nodes.
- Primary service is active during normal operations, when a region is up and running.
- Recovery service is active after taking over from primary service in the event of a region outage.
-
Passive: A CRDR peer service is passive when it runs on CRDR standby nodes only. Either CRDR peer service can be passive depending on a phase of the CRDR cycle.
-
Failed: A CRDR peer service is failed when it's defunct or unreachable after failing over in the event of a region outage. Only a primary service can be failed.
Limitations
-
Service plan requirements: To set up CRDR, your primary service must use at least a Startup plan. Hobbyist and Free plans are not supported.
Upgrading your planIf your Aiven for PostgreSQL service uses a Hobbyist plan or a Free plan, upgrade your free plan or change your Hobbyist plan to at least a Startup plan.
-
Console restrictions: When creating a recovery service through the Aiven Console, you must use the same service plan and cloud provider as your primary service.
Alternative setup methodsFor different service plans or cloud providers, create your recovery service using the Aiven CLI, the Aiven API, or the Aiven Provider for Terraform.
How it works
The CRDR feature is eligible for all startup, business, and premium service plans.

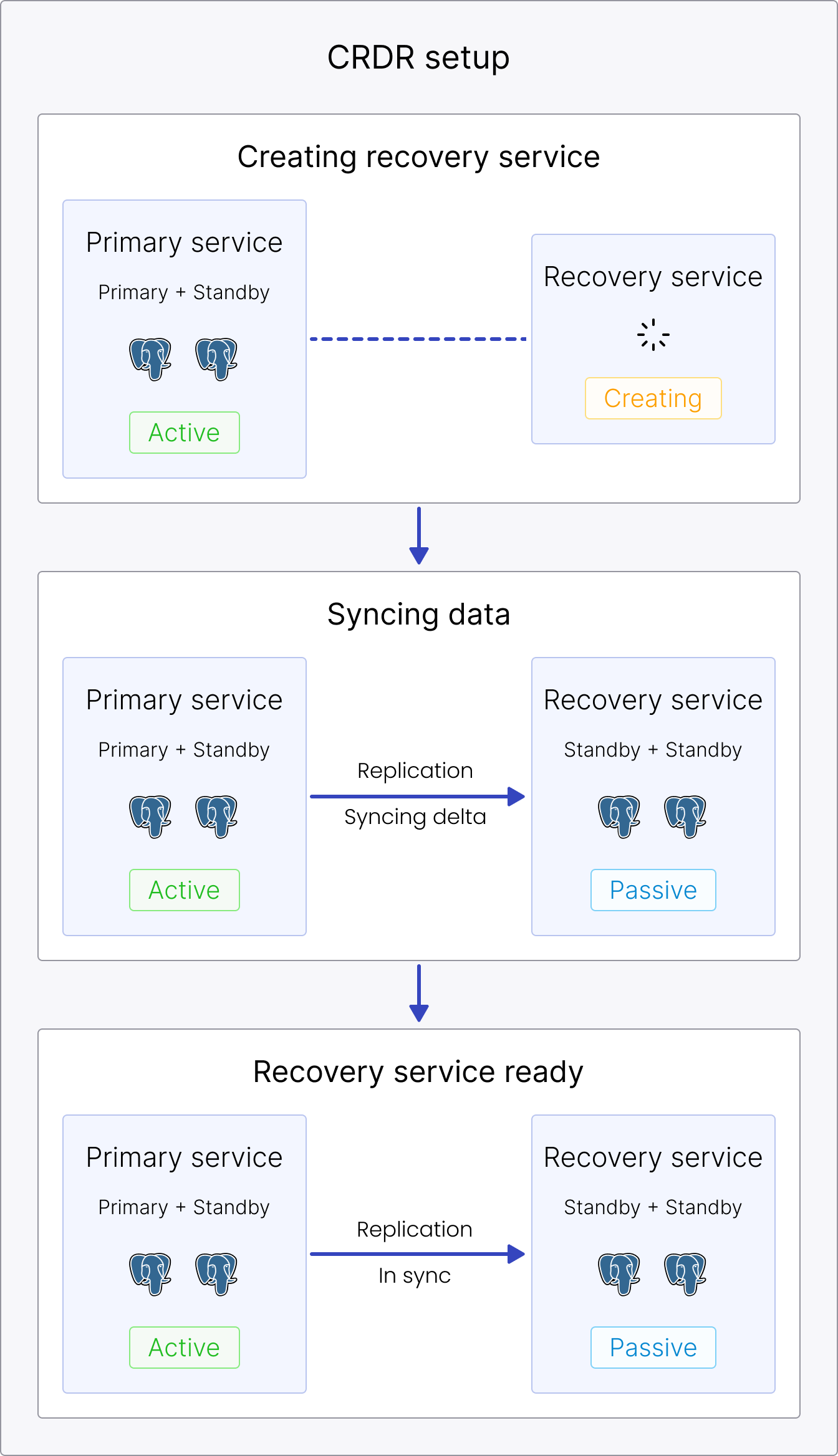
CRDR setup
You enable CRDR by creating a recovery service. The CRDR setup completes as soon as the recovery service is created and in sync with the primary service. At that point, the primary service is the Active service receiving incoming traffic and replicating to the recovery service, and the recovery service is the Passive service replicating from the primary service.
Recovery transition
CRDR supports two types of the recovery transition:
- Failover
- Triggered by you typically in the event of a region-wide outage
- Destroys the primary service and requires the primary service recreation to fail back.
- Switchover
- Triggered by you for any purposes other than a region-wide outage
- Leaves the primary service intact with no need for recreating it to switch back.
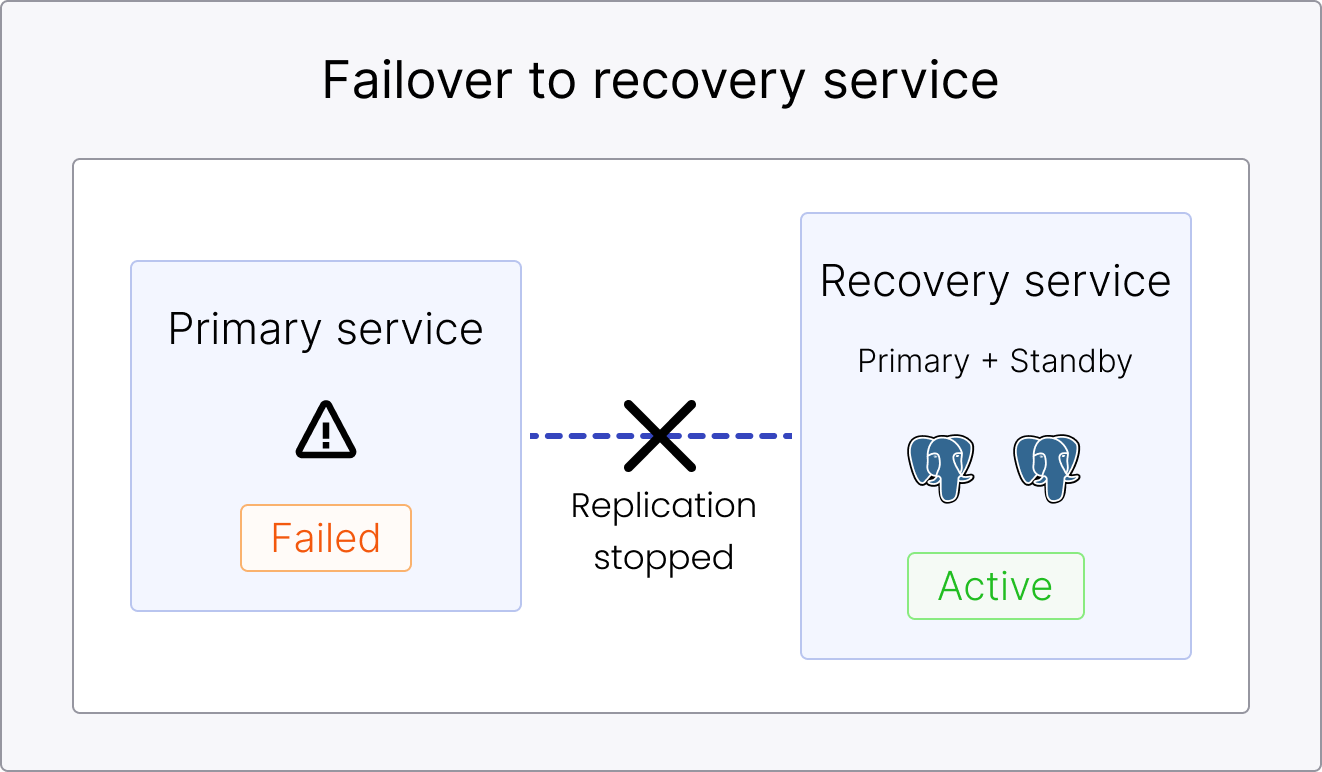
Failover to the recovery region
You typically trigger a failover to the recovery region in the event of a region-wide outage. This destroys the primary service, which becomes Failed, and promotes the recovery service to Active. To fail back to the primary service, it needs to be recreated first.
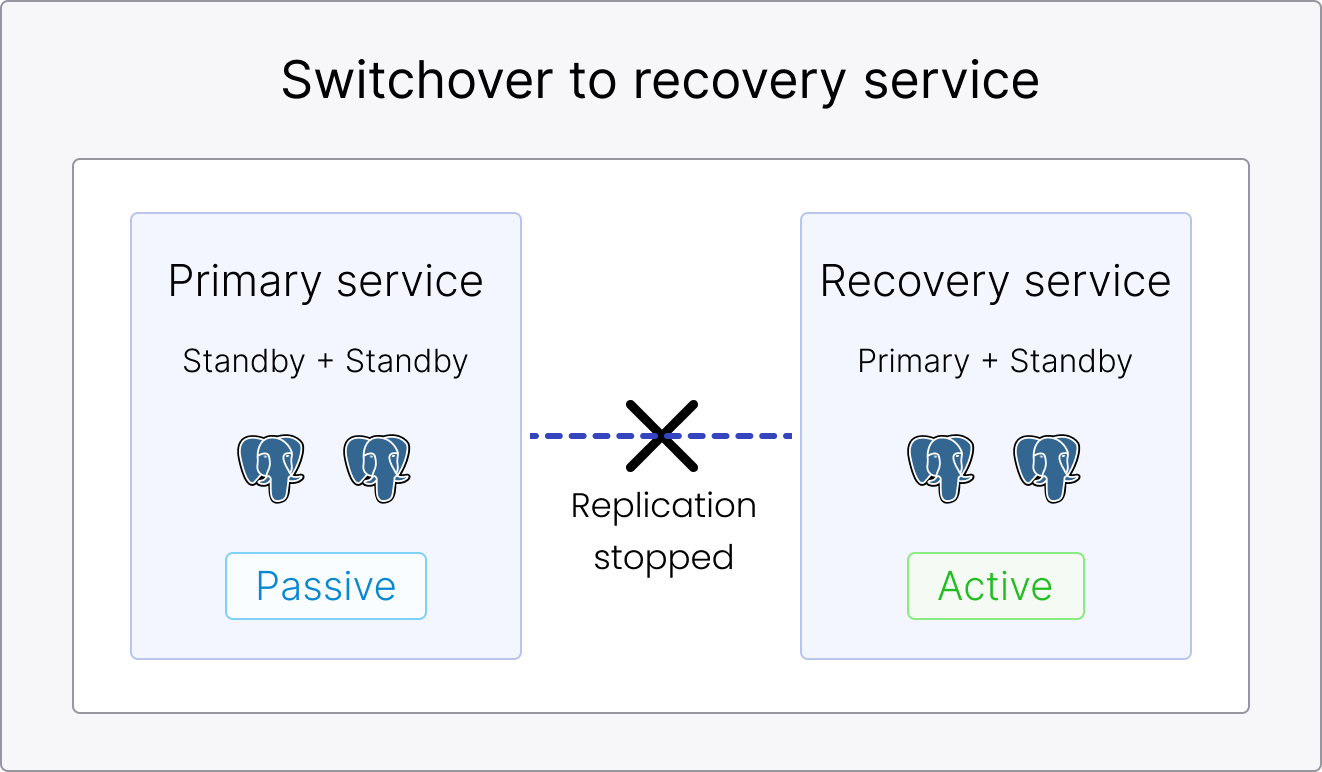
Switchover to the recovery region
You trigger a switchover to the recovery service for testing, simulating a disaster scenario, or verifying the disaster resilience of your infrastructure. This demotes the primary service to Passive and promotes the recovery service to Active. To switch back to the primary service, no service recreation is needed.
Recovery reversion
You trigger a recovery reversion to shift your workload back to the primary region and restore the CRDR setup to its original configuration.
There are two types of the recovery reversion:
- Failback
- Reverts a failover.
- Recreates the primary service.
- Switchback
- Reverts a switchover.
- No need to recreate the primary service.
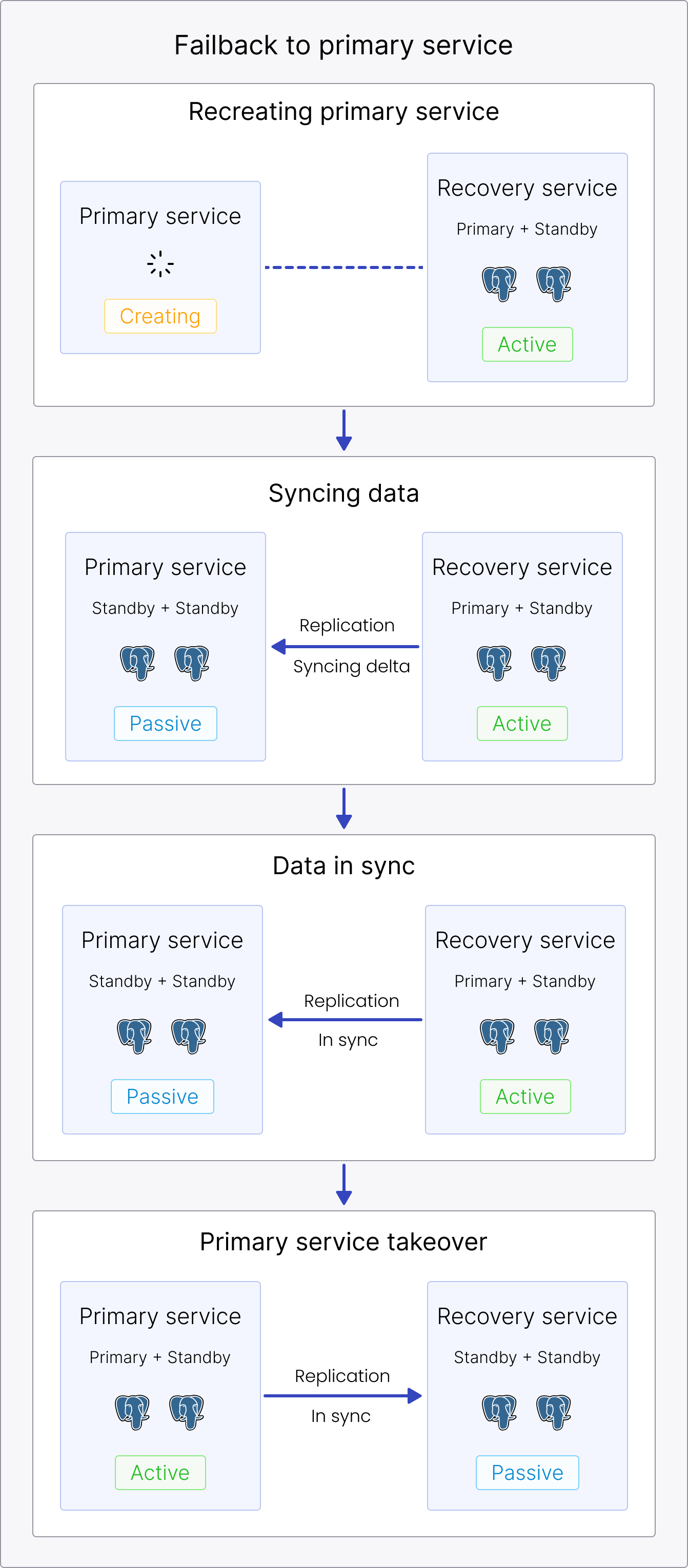
Failback to the primary region
The failback process consists of two steps you initiate at your convenience:
-
You initiate this step to restore primary service nodes from the local backups and to synchronize (replicate) the most recent data from the active service (recovery service). When completed, the primary service is restored and in near real-time sync with the recovery service.
-
You initiate a takeover as soon as the primary service is recreated. This switches the direction of the replication to effectively route the traffic back to the primary region. When completed, both the primary service and the recovery service are up and running again: the primary service as an active service, and the recovery service as a passive service.
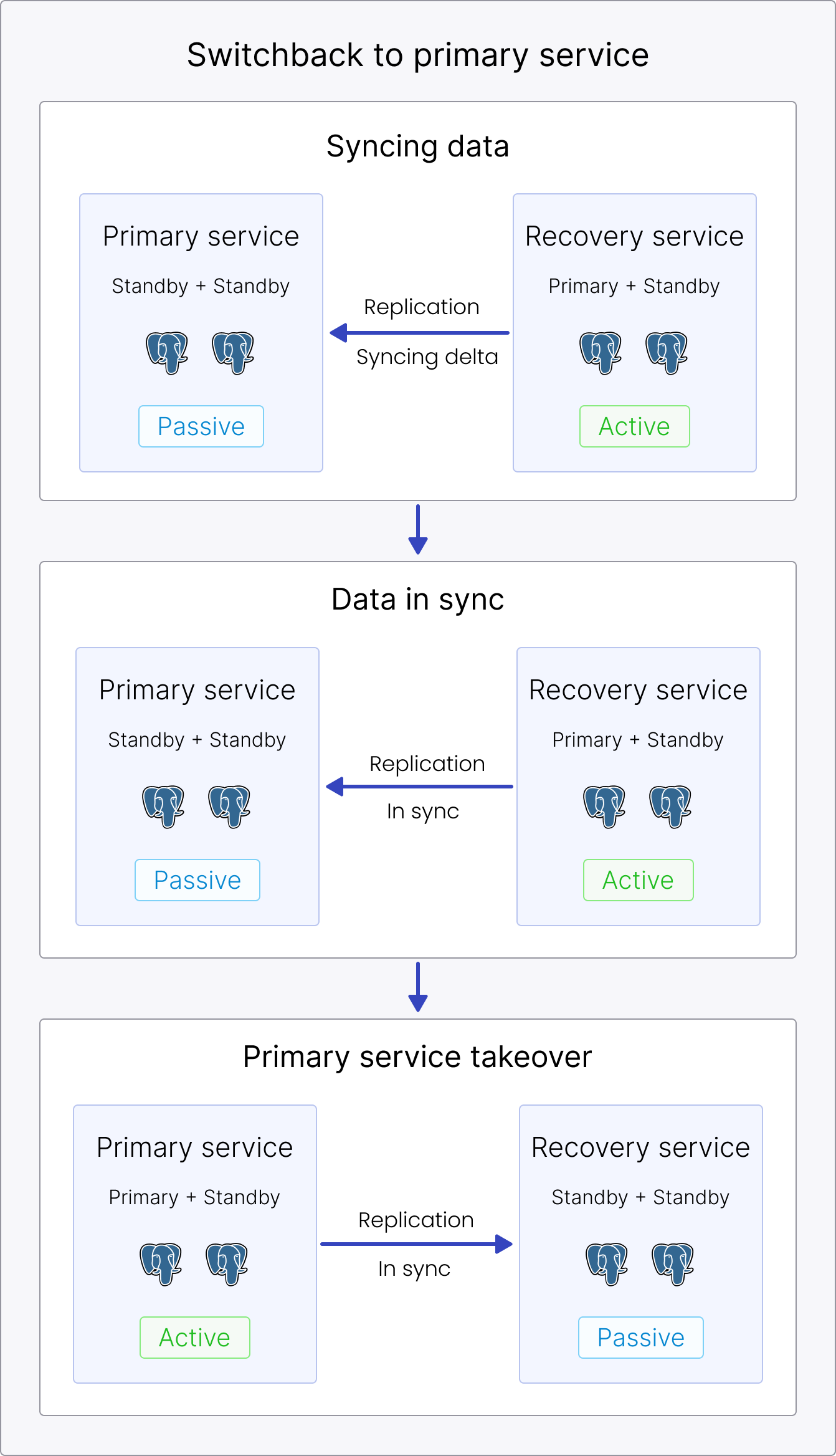
Switchback to the primary region
You initiate a switchback at your convenience to switch the direction of the replication and route the traffic back to the primary region. When completed, both the primary service and the recovery service are up and running again: the primary service as an active service, and the recovery service as a passive service.
DNS name and service URI
Active service DNS name
CRDR allows you to access your active service always using the same Service URI, which doesn't change in the event of a failover to the recovery region.
Service URI is a locator that is shared between the primary service and the recovery service. It always points to the replicating node of the active service. This node is the only read-write node in both CRDR regions.
The Service URI of an active service can remain unchanged in the event of a region outage because the DNS record of this Service URI is updated to point to the active service. This allows your applications to work uninterrupted and adapt to the change automatically without updating its code or data.
Standby nodes DNS names
Regardless of the CRDR cycle phase, you can always connect and access separately each standby node in the CRDR peer services. This can help you compensate for potential network delays by using the service geographically closer to your applications.
Standby nodes in the CRDR service pair can have two different URIs, depending on the CRDR service (region) they belong to:
- For the primary service standby URI, the DNS record always points to the standby nodes in the primary region.
- For the recovery service standby URI, the DNS record always points to the standby nodes in the recovery region.
Both the primary service standby URI and the recovery service standby URI are dedicated, not shared, and read-only.
Backups in the recovery region
After a failover to the recovery region in the event of a primary region outage, service backups start to be taken in the recovery region. You can use this backup history for operations and data resiliency purposes.
Related pages